There’s a version of enterprise AI that lives in conference presentations and press releases. Polished demos, impressive benchmarks, a chatbot that answers every question with eerie confidence. And then there’s the version that actually runs inside companies — slower, messier, and quietly struggling with the same fundamental problem it had two years ago: getting AI to reliably answer questions from your documents, not just the internet.
That gap — between the demo and the deployment — is exactly where RAGFlow has found its footing.
Table of Contents
What RAGFlow Is (and Why It’s Different)
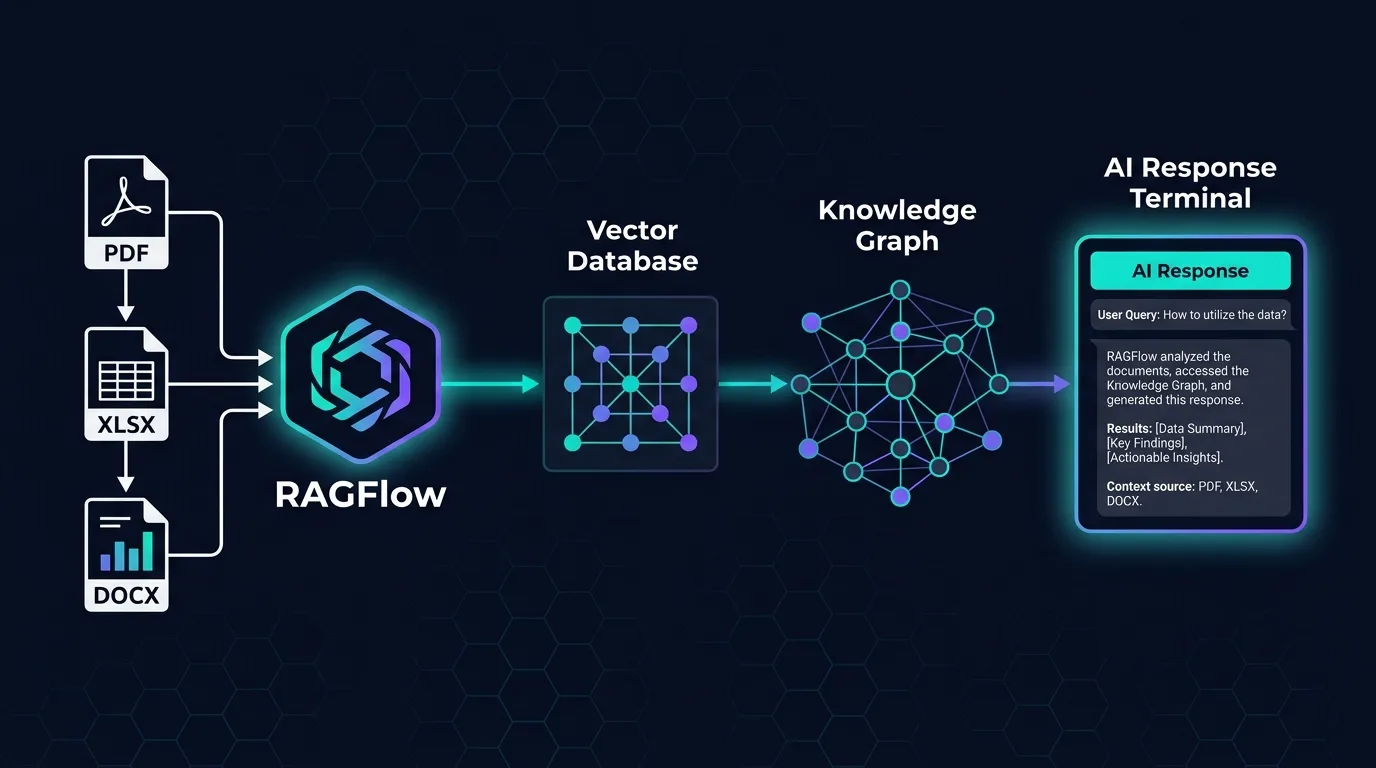
RAGFlow is an open-source retrieval-augmented generation engine built by the team at InfiniFlow. On the surface, it’s a RAG framework. But calling it that is a bit like calling a commercial kitchen a “place to cook food.” Technically accurate, wildly underselling the engineering inside.
Most RAG systems work roughly the same way: split your documents into chunks, embed them, store them in a vector database, retrieve the relevant ones at query time, and hand them to an LLM. It’s elegant in theory. In practice, it falls apart the moment your documents are anything other than clean, well-formatted plain text.
RAGFlow was built around a different starting premise: that the document understanding step is the problem, not the retrieval step. Fix how you read documents, and everything downstream gets better.
That’s not a subtle philosophical difference. It shapes every design decision in the system.
The Document Understanding Problem Nobody Talks About
Ask a typical engineer how RAG handles a complex PDF — say, a 200-page financial report with embedded tables, footnotes, multi-column layouts, and scanned pages — and you’ll get a slightly uncomfortable pause.
The honest answer is: not well. Most pipelines treat a PDF as a blob of text, strip out the formatting, and chunk it by character count or paragraph breaks. The result is retrieval that works fine for clean prose and falls apart for anything structured. A table gets split across two chunks. A figure caption loses its context. A footnote gets mixed into the wrong section. The LLM gets handed fragments and returns hallucinations dressed up as answers.
RAGFlow tackles this with what it calls “deep document understanding” — a combination of OCR, layout analysis, and document-type-specific parsing that actually tries to understand what it’s looking at before deciding how to chunk it. It can recognize table structures and keep them intact. It handles multi-column layouts. It treats a scanned image of a page differently than a native PDF.
This sounds like a detail. It isn’t. For enterprises whose knowledge lives in contracts, research reports, compliance documents, and financial filings, this is the entire ballgame.
Hybrid Retrieval: Why Vectors Alone Aren’t Enough
The early days of RAG were heavily vector-centric. Embed everything, retrieve by semantic similarity, done. It worked well enough that the approach became the default. But pure semantic search has a quiet failure mode: it’s great at finding documents that feel related, and sometimes terrible at finding the exact thing you need.
If a user asks about a specific clause number, a product SKU, or a precise date, semantic similarity can lead the retrieval system astray. These are cases where keyword matching — old-fashioned, BM25-style full-text search — actually outperforms dense vector retrieval.
RAGFlow combines both approaches. It runs hybrid retrieval that blends vector search with sparse keyword search, then uses a re-ranking model to decide what actually gets passed to the LLM. The result is noticeably better precision on the kinds of queries that trip up pure-vector systems — named entities, exact terminology, technical jargon.
It also integrates knowledge graph capabilities, which opens up a different class of queries altogether. Instead of just retrieving relevant text chunks, a knowledge graph lets the system reason about relationships: who approved this contract, what projects is this vendor associated with, how does this regulation connect to this internal policy. That relational layer is where enterprise RAG stops being a search tool and starts being something closer to institutional memory.
Why Enterprises Are Choosing Open Source
There’s a broader shift happening that RAGFlow is riding rather than creating. Enterprise AI teams burned by the first generation of proprietary AI platforms have developed a healthy skepticism toward vendor lock-in.
The pattern became familiar. A company would integrate deeply with a hosted AI service, customize it, build workflows around it, and then face a pricing change, a model deprecation, or a capability shift that required rebuilding significant chunks of their stack. The flexibility that made the hosted service attractive in year one became a liability in year two.
Open source solves a specific version of this problem. You own the code. You run it in your own infrastructure. You can modify it, audit it, and version-control it like any other piece of software. For industries with strict data residency requirements — healthcare, finance, government — running a RAG engine in your own cloud or on-premise isn’t just a preference, it’s often a regulatory necessity.
RAGFlow checks those boxes, and it checks them without requiring a team of ML engineers to operate. The architecture is designed to be deployable by standard DevOps teams, with Docker-based deployment and a UI that lets non-technical users manage knowledge bases directly. That’s a meaningful distinction in an enterprise context where the AI team and the business teams often work in very different tooling ecosystems.
Where It’s Actually Being Used
The use cases that have driven RAGFlow adoption in 2026 cluster pretty predictably around document-heavy industries.
Legal and compliance teams use it to build internal knowledge bases over case law, regulatory guidance, and contract archives. The deep document parsing is particularly valuable here — legal documents are notoriously structured, and losing that structure in the chunking step produces answers that are confidently wrong in ways that matter.
Financial services firms deploy it over analyst reports, SEC filings, and internal research. The hybrid retrieval helps with the mix of quantitative precision (exact figures, specific dates, ticker symbols) and qualitative analysis that financial queries tend to involve.
Healthcare organizations — particularly those building over clinical guidelines, research literature, and internal protocols — are drawn to the on-premise deployment model. Keeping patient-adjacent data inside controlled infrastructure isn’t optional in this space.
Internal knowledge management might be the most universal use case. Enterprises of all kinds are drowning in documentation that nobody can find. HR policies, engineering runbooks, product specs, onboarding materials, project post-mortems. RAGFlow-powered internal search tools are becoming the practical answer to the question: “How do we make institutional knowledge actually accessible?”
The Honest Limitations
No tool deserves to be written about without acknowledging where it struggles, and RAGFlow has real rough edges.
The setup experience, while better than it was, still assumes a certain level of technical fluency. If you’re a small team without dedicated infrastructure support, getting RAGFlow running smoothly — especially in a production environment with high query volumes — takes real work. The documentation has improved significantly but still has gaps, particularly around advanced configuration and performance tuning.
The knowledge graph features are powerful but require meaningful investment to get right. Building a useful graph over enterprise data isn’t just a technical task; it requires domain expertise to define the right entities and relationships. Teams that underestimate this end up with a graph that adds complexity without adding value.
And like every RAG system, RAGFlow is ultimately dependent on the quality of the underlying LLM it’s connected to. It can improve retrieval dramatically, but it can’t fully compensate for a model that hallucinates or struggles with complex reasoning. The retrieval layer and the generation layer are both in the chain, and both matter.
What 2026 Actually Looks Like for RAGFlow
The most significant evolution in RAGFlow’s trajectory over the past year isn’t a single feature — it’s the shift toward agentic patterns. RAG as a passive lookup tool is giving way to RAG as an active component in multi-step reasoning pipelines.
In practical terms, this means RAGFlow increasingly gets embedded inside agent workflows where it’s not just answering a single question but supporting a chain of retrieval operations. An agent might query a knowledge base, identify a gap, formulate a follow-up query, retrieve more context, and synthesize across multiple retrievals before returning an answer. That’s a fundamentally different use pattern than “user asks question, system retrieves chunks, LLM responds.”
Multi-modal support is also maturing. The ability to retrieve from and reason over images, charts, and diagrams alongside text matters enormously for the kinds of documents enterprises actually use. A financial report where half the information lives in charts isn’t well-served by a text-only retrieval system.
The roadmap also points toward tighter integration with the broader open-source AI ecosystem — better connectors to popular LLM serving frameworks, more flexible embedding model support, and improved observability tooling so teams can actually understand why their retrieval pipeline is returning what it’s returning. That last point is underrated. Debugging RAG systems is notoriously opaque, and better observability is as important as any retrieval improvement.
The Backbone Analogy Is Apt
The claim that RAGFlow is becoming the backbone of enterprise AI isn’t hype, but it does require a specific reading. It’s not claiming to be the brain — the LLM is still doing the generation, the reasoning, the synthesis. What RAGFlow provides is the connective tissue between that reasoning capability and the knowledge that makes it useful in a specific organizational context.
Backbones are rarely glamorous. Nobody gives a keynote about their RAG infrastructure. But the difference between an AI deployment that actually works in production and one that quietly gets abandoned six months after launch often comes down to exactly this layer — how reliably, accurately, and scalably can the system retrieve the right information at the right moment.
In 2026, enterprises that are getting real value from AI aren’t the ones with the most powerful models. They’re the ones that solved the retrieval problem. RAGFlow is, increasingly, how they’re doing it.
If you’d like to dive deeper, check out Master RAGFlow: The Ultimate Beginner’s Guide to Powerful, Accurate AI.
Have you deployed RAGFlow or another RAG engine in an enterprise context? The implementation details — what worked, what didn’t — are usually more interesting than the marketing.